Regular expressions and finite automata
I've just finished the bulk of a personal project, a C++ program which stores and manipulates regular expressions and finite automata. Clocking in at over 1000 lines of code in total, it was a bit more work than I thought it'd be, but I'm pretty happy with it overall (modulo a bit more debugging and refactoring). The biggest problem has been finding a way to explain the project to non-computer-scientists.
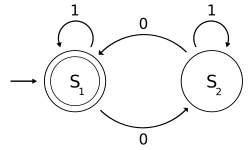
If you're reading this blog, you've probably heard of Turing Machines, and the idea that they can do any calculation possible in this universe (as far as we know). What about simpler versions of Turing Machines? It turns out that you can define a number of different machines which are strictly less powerful. Near the bottom of this hierarchy are finite automata, which consist only of a finite number of states, with transitions between them. A finite automaton - they come in two varieties, deterministic (DFA) and non-deterministic (NFA) - "accepts" a string of letters if there's a path from the starting state to an end state which consists of the letters in that string. For instance, in the diagram below, S1 is both the start state and end state. Strings accepted include any number of 1s in a row; any string consisting of 1s, then a 0, then more 1s, then another 0; in short, any possible string which contains an even number of 0s. This can be written more succinctly using the regular expression (1*01*01*)*, where * means "repeat any number of times (including possibly 0 times)".
Another regular expression might look like 0* + 1*, which means "any number of 0s or any number of 1s (but no string mixing 0s and 1s)". There's a very cool result which says that any finite automaton is equivalent to a regular expression, and vice versa. Partly because of this, finite automata turn out to be pretty useful in building compilers, amongst other things, and I wanted to brush up on them. So what does my program do? It implements classes for regular expressions and FAs. It takes as input a regular expression, and converts it to an NFA - or else it accepts the NFA as input directly. From there, it can do a bunch of operations on the NFA, including simplifying it, taking the complement, or converting it to a DFA. It can also combine two NFAs in a variety of ways, including via union, intersection and concatenation. These combinations and conversions end up helping to achieve the final goal, which is testing whether two regular expressions or finite automata are equal. If you think of NFAs A and B as representing two sets of strings, then A and B are equal iff the complement of A doesn't overlap with B AND the complement of B doesn't overlap with A. That boils down to constructing the specified NFA and testing whether it's empty.
The theory behind this was based on my Models of Computation course last year, but there may well be more efficient implementations which I haven't learned about. In particular, I'm curious about two things: is there a NFA-DFA conversion algorithm which is sub-exponential on average, and is there an efficient way to test regular expression equality without the conversion to finite automata? I'm predicting negative answers to both of those, but let me know if I'm wrong on that.
Main lesson learned from this project: plan out a broad class structure before starting. I wasted a lot of time messing around with polymorphism when it wasn't strictly necessary. Also, test early and often! If there's one golden rule of programming, that's it.
If you're reading this blog, you've probably heard of Turing Machines, and the idea that they can do any calculation possible in this universe (as far as we know). What about simpler versions of Turing Machines? It turns out that you can define a number of different machines which are strictly less powerful. Near the bottom of this hierarchy are finite automata, which consist only of a finite number of states, with transitions between them. A finite automaton - they come in two varieties, deterministic (DFA) and non-deterministic (NFA) - "accepts" a string of letters if there's a path from the starting state to an end state which consists of the letters in that string. For instance, in the diagram below, S1 is both the start state and end state. Strings accepted include any number of 1s in a row; any string consisting of 1s, then a 0, then more 1s, then another 0; in short, any possible string which contains an even number of 0s. This can be written more succinctly using the regular expression (1*01*01*)*, where * means "repeat any number of times (including possibly 0 times)".
Another regular expression might look like 0* + 1*, which means "any number of 0s or any number of 1s (but no string mixing 0s and 1s)". There's a very cool result which says that any finite automaton is equivalent to a regular expression, and vice versa. Partly because of this, finite automata turn out to be pretty useful in building compilers, amongst other things, and I wanted to brush up on them. So what does my program do? It implements classes for regular expressions and FAs. It takes as input a regular expression, and converts it to an NFA - or else it accepts the NFA as input directly. From there, it can do a bunch of operations on the NFA, including simplifying it, taking the complement, or converting it to a DFA. It can also combine two NFAs in a variety of ways, including via union, intersection and concatenation. These combinations and conversions end up helping to achieve the final goal, which is testing whether two regular expressions or finite automata are equal. If you think of NFAs A and B as representing two sets of strings, then A and B are equal iff the complement of A doesn't overlap with B AND the complement of B doesn't overlap with A. That boils down to constructing the specified NFA and testing whether it's empty.
The theory behind this was based on my Models of Computation course last year, but there may well be more efficient implementations which I haven't learned about. In particular, I'm curious about two things: is there a NFA-DFA conversion algorithm which is sub-exponential on average, and is there an efficient way to test regular expression equality without the conversion to finite automata? I'm predicting negative answers to both of those, but let me know if I'm wrong on that.
Main lesson learned from this project: plan out a broad class structure before starting. I wasted a lot of time messing around with polymorphism when it wasn't strictly necessary. Also, test early and often! If there's one golden rule of programming, that's it.

Comments
Post a Comment